As a technical writer who occasionally does some development on the side, I appreciate a fast Time to First Hello World (TTFHW)—the time it would take to create and run a simple program using a new (to me) API. The time to get started, in other words. The Nest API documentation I recently reviewed reminded me of a much less frequently mentioned notion, the time to get finished.
If you’re not familiar with TTFHW, it is basically, how long it takes a new user to:
Find your product
Resonate with its value proposition
Test it out to verify it provides them with a viable solution
The metric for this is operationalized by how long it takes someone to write a simple program to demonstrate step 3. From a measurement standpoint, this is a reasonable goal in that:
It’s tangible and relatively unambiguous in its meaning (the reader was successful in accomplishing the goal).
It can be measured accurately if your help documentation provides a way to link the documentation to the use of the API, through a user-specific key or interactive development environment.
It can show a tangible engagement metric to show that your product is attracting and engaging potential customers.
While it’s good to use that as a metric for engagement and potential adoption, it’s important to not treat it as the only metric that counts because it doesn’t necessarily represent retention or other aspects where the money is made or lost.
I saw some buzz about the Nest developers’ API explorer and its corresponding developer documentation so I took a look. For many reasons, new API documentation formats attract a lot of buzz (and envy) among technical writing circles. From the technical writers wondering, “How can I make my documentation to look like this?” to the executives demanding, “Why don’t our docs look like this?!” Rarely, do I hear, “should our docs look like that?” But, that’s what I’m here for (it seems).
Should your API docs look like the Nest developers docs?
The answer is, of course, maybe.
I don’t have any inside information about why or how the writers of the Nest documentation did what they did, so the following analysis is based on my observation and inference.
What it does well
It has a very clean UI. Clean presentations inspire confidence and professionalism. The styling is consistent and aligned with the consumer site’s branding, which implies they consider their API docs to be a part of their brand promise. I think that’s a good sign. Externally, it shows that the company considers the API to be part of the product’s brand and not a bolt-on or afterthought. As a developer, this is reassuring.
As first impressions go, it has a very nice curb appeal.
Coal miners used to bring canaries with them into the mines to detect toxic gasses commonly found in mines. Canaries would die when the gasses were present, but while still at levels not fatal to humans. They were an early-warning sign. The challenge is that you would have to keep an eye (or an ear) on them to heed their warning. If you were busily mining your coal (a rather noisy job to begin with), you could easily overlook the warning sign of a dead canary—much to your peril.
Think of your technical writer as a canary (that can also type).
I read a lot about how API documentation is deficient, how it should be automated, and how it should be made easier to produce and update. I’m all for making it easier to write and maintain, but I think replacing the canary with a device or process that won’t let you know when there’s trouble ahead is solving the wrong problem.
Why IS your API hard to document?
It could be that it’s toxic and you haven’t noticed the dead canary.
I read The Top 20 Reasons Startups Fail that studied the reasons that failed startups reported as why they failed and the reasons looked surprisingly similar to challenges I’ve seen in my career of documenting and researching APIs.
Coincidence? Let’s take a look.
There’s no market need
This is the #1 cause for failure cited by the startups reviewed in the CB Insights study. What does this have to do with an API?
If there’s no market need, what user cases will the documentation address? To whom will the technical writer be explaining all these features? With what burning customer pain-points or unmet needs will the documentation connect? What sort of demos and tutorials will need to be written (or referred to) that demonstrate solutions to customer problems? Why will anyone care?
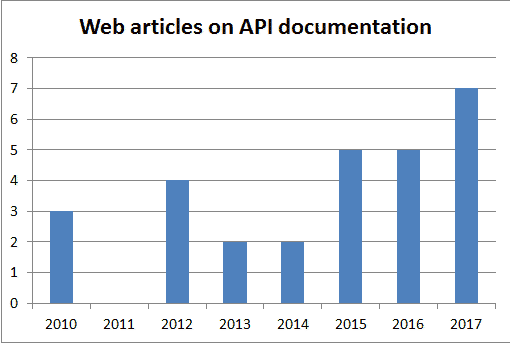
My list of API documentation articles -non academic has grown from 18 to 30 articles. Most new ones are from the past year, but I found a few earlier articles that I seemed to have missed in my last update.
Plotting them over time shows some recent growth in frequency as with the academic articles on API documentation, however there are 66% more academic articles on the topic in my [ever expanding] collection, so it might still be too soon to draw and comparisons.
I’m still intrigued by my discovery from yesterday that I describe in API documentation research-Where’s Tech Comm? The idea seems like it might have some legs for some tenure-worthy academic paper(s), so I thought I’d dig into it a bit more to see what I might be signing myself up for.
And the plot thickened. Which, for an academic, is a good thing in that it means it has potential for papers, talks, and maybe even a book? (Yippee!). But, I’m getting ahead of myself. (No book tours, yet.).
Disclaimer: what follows is a peek into my notebook and represents a work-in-progress. Any claims I make (or appear to make) are subject to change as the research progresses.
I started to take the study a little more seriously and methodically–i.e., I started collecting data. For now, my working research questions evolved from, “Why are only computer science researchers studying API documentation and why don’t they refer to technical communication research much (or at all)?” to “Have computer science researchers ever heard of technical communication research?!” and vice versa.
Google Scholar is for Computer Science research
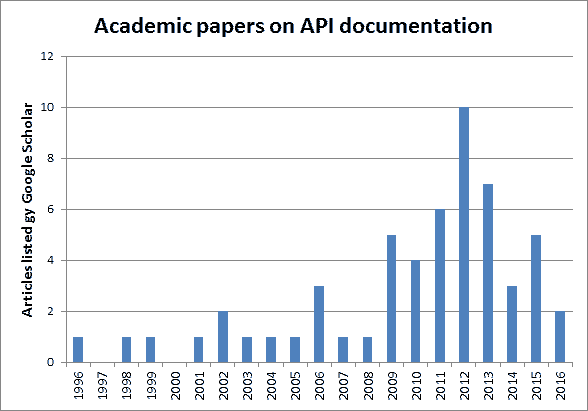
In searching for “API Documentation” on Google Scholar, I collected something like 50 articles and papers having to do with API documentation over the years (The earliest paper I’ve found, so far, is from 1996). The following figure shows the distribution of papers by year published.
Academic papers about API Documentation
It’s good to see the topic being researched (finally!). I started studying them around 2008-2009 when, as you can see in the chart, there weren’t many to use as a reference. As academic fields of study go, this is definitely a niche topic. And, yes the bars add up to more than 50-something because I’m still in the process of cleaning my data set. The numbers are going to be rough in the meantime, but they seem representative if they aren’t precise, yet.
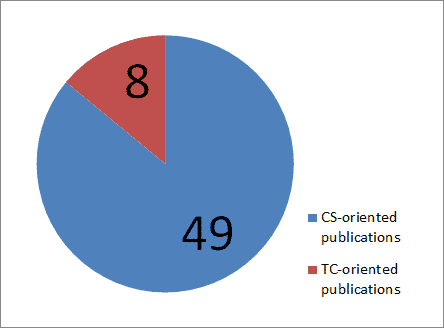
The more I looked at the academic papers I was collecting, the trend of them being from computer science(y) journals and conferences was even more skewed as this chart shows.
Distribution of API documentation research papers by type of publication
From the look of that graph, you could think that TC is hardly talking about API documentation. It’s even more stark when you take into account that I wrote 5 of the 8 articles in the TC slice of the pie.
Yet, I hear lots of API documentation talk on TC social media channels and Linked in has several groups dedicated to the topic so something isn’t passing the sniff test.
Is TC research on API documentation only published in blogs
As a reality check, I went to regular Google and search on API documentation and found a whole bunch of relevant topics. I haven’t formally collected them into my list, so I can’t say how many, yet, but it was clearly being talked about on the web. From a quick skim, the articles from the general web seemed to be more TC oriented than CS oriented (but, don’t quote me, on that, yet).
What slowed my progress down, momentarily, was I wanted to study the scholarly articles they were using as their references. I think that’s where some tenure-worthy research opportunities will be found. I’m (slowly and tediously) categorizing the references cited by each of the scholarly articles to get an idea of what they’re basing their research on. While that’s going to be tedious (i.e. incredibly tedious: 50+ articles each with 30+ references = 1,500+ citations to clean up and organize–if only they just attached a metadata file).
Unfortunately, the blog posts and informal references from the TC community in “regular” Google don’t tend to list as many citations as the academic articles, so looking for their foundations is going to take some more detective work. But, one thing at a time.
What it’s looking like, however, is that the academic CS scholars don’t refer to much in the way of TC research. I suppose that if they don’t provide any citations, you could say that the TC research doesn’t either. Maybe I’ll need to turn to some tcmyths for more info?
In any case, regardless of where this goes, I’ll end up with a killer bibliography of API documentation!
Google Scholar was reading my mind this morning and provided me a list of recommended papers. This was both interesting and troubling at the same time. It was interesting that they knew what I’d find interesting (they have been listening!) and troubling that I was only familiar with a couple from the list (i.e. I need to read more, apparently). Most disturbing was that in the articles on API documentation, most all references that those articles cited were from computer science literature and not from documentation or technical writing. One article cited my dissertation, so I can’t say there were no references to documentation research.
It could be there’s nothing to find. Searching Google Scholar for articles on “API documentation” yields no articles from non computer-science journals until one of mine appears on the fourth page of search results. So, it’s a reasonable question to ask if there are other sources to find.
By this, I mean, should you describe in the formal documentation the way a feature actually works or the way it is supposed to work?
tl;dr: Yes.
There is a lot of research that says software developers (and, I would imagine almost anyone else, but I haven’t studied that research) expect the documentation to be accurate, so reference documentation should describe how something ACTUALLY works. If “how it works” changes, the documentation should be updated to reflect that. Simple, right?
Well, if a feature is shipped that (let’s say) still has some room for improvement, your accurate documentation will highlight that. A real fear in the hearts of some product managers is that your accurate documentation could turn some customers away saying, “we need something that does X and your product’s documentation says that it doesn’t do X (yet).” Your product manager will have to weigh the cost of that vs. the cost of having the customer build their system around your product expecting “X” only to find out that it doesn’t. A decision that could get your product into market and/or into an unflattering TechCrunch article.
The problem with reference topics (of almost any sort) is that, individually, they don’t do much and don’t get a lot of attention (except, of course, when they do). Collectively, they tell your customers how much you value their time and their business.
I’m in the process of writing one of several academic articles that my current profession (professor) demands of me. An essential part of the process is indulging in the diversions and distractions necessary to retain some sanity throughout the process. Today’s diversion was updating my global bibliography. Unfortunately, that idea turned out to have some depressing side effects, which I’m here to share with you.
It turns out that there’s a lot of research being done in how to automatically generate API documentation. Having written a lot of it and read a lot more, I can certainly understand the motivations. What I didn’t realize was from how many different directions the problem was being attacked. Someone even patented an idea for it (US 8819629 B2, in case you were wondering).
I published my first API around 1988 for a peripheral to the IBM PC in which the API consisted of software interrupts to MS-DOS. (A software interrupt is similar in function to a procedure call, but used for operating system and device driver functions. I didn’t write the documentation (at least not the published version), but a couple of co-workers and I wrote the interface.
Later, I want to say in 1997-ish, I wrote the API provided by the Performance Data Helper (PDH) dynamic link library (DLL) that shipped in Microsoft Windows NT 4.0 (IIRC). I didn’t write the documentation for this API either as I was still developing software at the time. A super technical writer did the heavy lifting of making sense out of the functions the PDH.DLL provided.
While this isn’t a particularly impressive resume of API development, it shows that APIs and I go way back. They are a very useful tool for solving many problems. Yet, over the past 30+ years that I’ve been using, developing, and documenting APIs, there hasn’t really been much written about their documentation–until recently.
In my informal count (i.e. what I could find on Google while having my morning coffee a few days ago). I came across 17 articles and blog posts on the topic in just the past seven years (full list at the end of the post).
That measuring API documentation is difficult is one of the things I’ve learned from writing developer docs for more than 11 years. Running the study for my dissertation gave me a detailed insight as to some of the reasons for this.
The first challenge to overcome is answering the question, “What do you want to measure?” A question that is followed immediately by, “…and under what conditions?” Valid and essential, but not simple, questions. Stepping back from that question, and a higher-level question comes into view, “What’s the goal?” …of the topic? …of the content set? and then back to the original question, of the measurement?
For my dissertation, I spent considerable effort scoping the experiment down to something manageable, measurable, and meaningful–ending up at the relevance decision. Clearly there is more to the API documentation experience than just deciding if a topic is relevant, but that’s a pivotal moment in the content experience. The relevance decision also seemed to be the most easily identifiable, discrete event that I could identify in the overall API reference topic experience. It’s a pivotal point in the experience, but by no mean the only one.
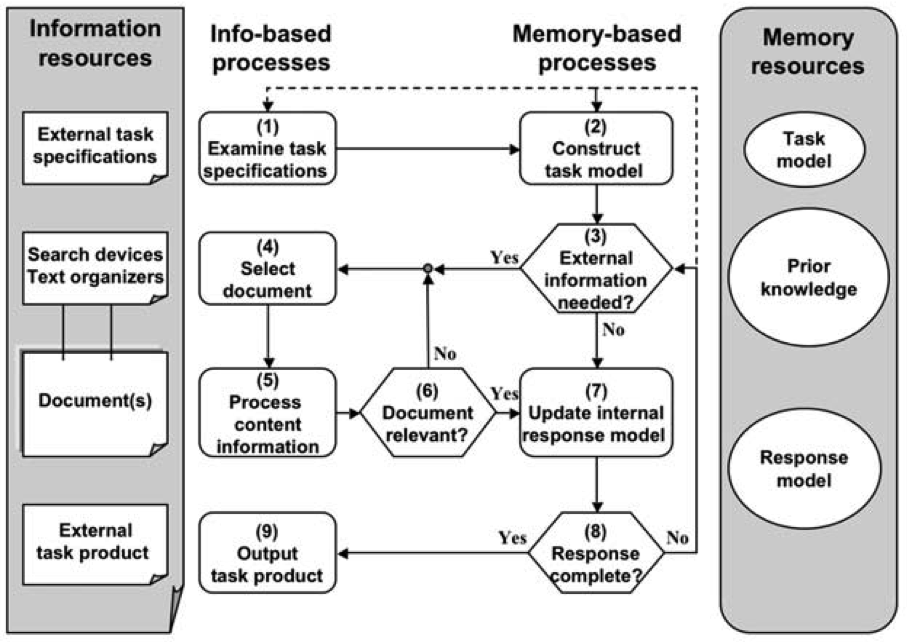
The processing model I used was based on the TRACE model presented by Rouet (2006). Similar cognitive-processing models were also identified in other API documentation and software development research papers. In this model, the experiment focuses on step 6.
The Task-based Relevance Assessment and Content Extraction (TRACE Model) of document processing Rouet, J.-F. (2006). The Skills of Document Use: From Text Comprehension to Web-Based Learning (1st ed.). Lawrence Erlbaum Associates.
Even in this context, my experiment studies a very small part of the overall cognitive processing of a document and an even smaller part of the overall task of information gathering to solve a larger problem or to answer a specific question.
To wrap this up by returning to the original question, that is…what was the question?
The goal of the topic is to provide information that can be easily accessible to the reader.
The easily accessible goal is measured by the time it takes for the reader to identify whether the topic provides the information they seek or not.
The experiment simulates the readers task by providing the test participants with programming scenarios in which to evaluate the topics
The topics being studied are varied randomly to reduce order effects and bias and participants see only one version of the topics to bias their experience by seeing other variations.
In this experiment, other elements of the TRACE model are managed by or excluded from the task.

 Coal miners used to bring canaries with them into the mines to detect toxic gasses commonly found in mines. Canaries would die when the gasses were present, but while still at levels not fatal to humans. They were an early-warning sign. The challenge is that you would have to keep an eye (or an ear) on them to heed their warning. If you were busily mining your coal (a rather noisy job to begin with), you could easily overlook the warning sign of a dead canary—much to your peril.
Coal miners used to bring canaries with them into the mines to detect toxic gasses commonly found in mines. Canaries would die when the gasses were present, but while still at levels not fatal to humans. They were an early-warning sign. The challenge is that you would have to keep an eye (or an ear) on them to heed their warning. If you were busily mining your coal (a rather noisy job to begin with), you could easily overlook the warning sign of a dead canary—much to your peril.