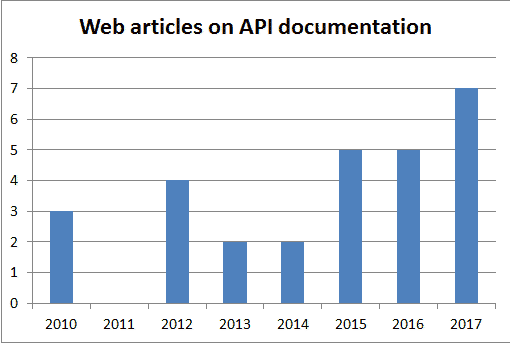
My list of API documentation articles -non academic has grown from 18 to 30 articles. Most new ones are from the past year, but I found a few earlier articles that I seemed to have missed in my last update.
Plotting them over time shows some recent growth in frequency as with the academic articles on API documentation, however there are 66% more academic articles on the topic in my [ever expanding] collection, so it might still be too soon to draw and comparisons.
I’m still intrigued by my discovery from yesterday that I describe in API documentation research-Where’s Tech Comm? The idea seems like it might have some legs for some tenure-worthy academic paper(s), so I thought I’d dig into it a bit more to see what I might be signing myself up for.
And the plot thickened. Which, for an academic, is a good thing in that it means it has potential for papers, talks, and maybe even a book? (Yippee!). But, I’m getting ahead of myself. (No book tours, yet.).
Disclaimer: what follows is a peek into my notebook and represents a work-in-progress. Any claims I make (or appear to make) are subject to change as the research progresses.
I started to take the study a little more seriously and methodically–i.e., I started collecting data. For now, my working research questions evolved from, “Why are only computer science researchers studying API documentation and why don’t they refer to technical communication research much (or at all)?” to “Have computer science researchers ever heard of technical communication research?!” and vice versa.
Google Scholar is for Computer Science research
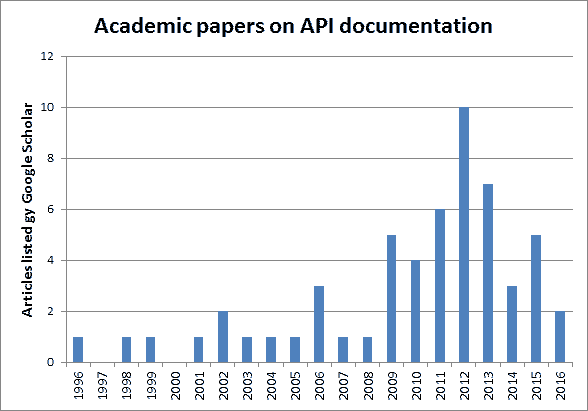
In searching for “API Documentation” on Google Scholar, I collected something like 50 articles and papers having to do with API documentation over the years (The earliest paper I’ve found, so far, is from 1996). The following figure shows the distribution of papers by year published.
Academic papers about API Documentation
It’s good to see the topic being researched (finally!). I started studying them around 2008-2009 when, as you can see in the chart, there weren’t many to use as a reference. As academic fields of study go, this is definitely a niche topic. And, yes the bars add up to more than 50-something because I’m still in the process of cleaning my data set. The numbers are going to be rough in the meantime, but they seem representative if they aren’t precise, yet.
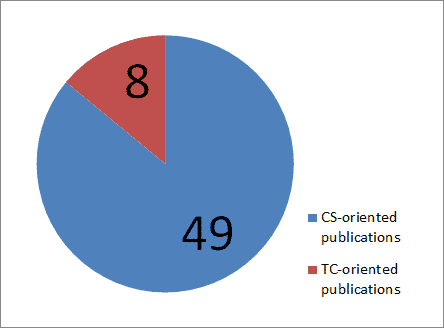
The more I looked at the academic papers I was collecting, the trend of them being from computer science(y) journals and conferences was even more skewed as this chart shows.
Distribution of API documentation research papers by type of publication
From the look of that graph, you could think that TC is hardly talking about API documentation. It’s even more stark when you take into account that I wrote 5 of the 8 articles in the TC slice of the pie.
Yet, I hear lots of API documentation talk on TC social media channels and Linked in has several groups dedicated to the topic so something isn’t passing the sniff test.
Is TC research on API documentation only published in blogs
As a reality check, I went to regular Google and search on API documentation and found a whole bunch of relevant topics. I haven’t formally collected them into my list, so I can’t say how many, yet, but it was clearly being talked about on the web. From a quick skim, the articles from the general web seemed to be more TC oriented than CS oriented (but, don’t quote me, on that, yet).
What slowed my progress down, momentarily, was I wanted to study the scholarly articles they were using as their references. I think that’s where some tenure-worthy research opportunities will be found. I’m (slowly and tediously) categorizing the references cited by each of the scholarly articles to get an idea of what they’re basing their research on. While that’s going to be tedious (i.e. incredibly tedious: 50+ articles each with 30+ references = 1,500+ citations to clean up and organize–if only they just attached a metadata file).
Unfortunately, the blog posts and informal references from the TC community in “regular” Google don’t tend to list as many citations as the academic articles, so looking for their foundations is going to take some more detective work. But, one thing at a time.
What it’s looking like, however, is that the academic CS scholars don’t refer to much in the way of TC research. I suppose that if they don’t provide any citations, you could say that the TC research doesn’t either. Maybe I’ll need to turn to some tcmyths for more info?
In any case, regardless of where this goes, I’ll end up with a killer bibliography of API documentation!
Google Scholar was reading my mind this morning and provided me a list of recommended papers. This was both interesting and troubling at the same time. It was interesting that they knew what I’d find interesting (they have been listening!) and troubling that I was only familiar with a couple from the list (i.e. I need to read more, apparently). Most disturbing was that in the articles on API documentation, most all references that those articles cited were from computer science literature and not from documentation or technical writing. One article cited my dissertation, so I can’t say there were no references to documentation research.
It could be there’s nothing to find. Searching Google Scholar for articles on “API documentation” yields no articles from non computer-science journals until one of mine appears on the fourth page of search results. So, it’s a reasonable question to ask if there are other sources to find.
A link to this post on using Google Translate (or not) popped into my Twitter feed this morning and I was just talking to my wife (a Spanish Language tutor and occasional translator) about using Google Translate. Together, those two events hatched this post on how it Google Translate can work for you.
Is Google Translate good enough?
In Bill Swallow’s post, he answers that question with it “depends on three core content facets: audience, subject matter, and quality. ” A comment to that post included a link to the results of an evaluation of machine translations from international English to Spanish, Norwegian, Welsh, and Russian, which showed, “the machine translations of international English are usually satisfactory.” Having worked on content intended for translation, the use of international English, should be emphasized.
Translating a web site with Google Translate
My wife has a client who is a sole proprietor with a simple website. Her client wants to expand and serve more Spanish-speaking clientele. As a small business, her client doesn’t have a lot of resources to support the web site–keeping it up-to-date in one language is more than enough work for her client, adding another language is basically a non-starter.
The content on her client’s site is somewhat technical, so running it through Google Translate produces marginal results. When my wife asked for some ideas, I suggested that rather than translate all the pages to create a Spanish version of the site (what her client originally asked for), she review and edit the site’s English text to improve the results that Google Translate produced. That way her client would need to maintain the website in only one language (English) while providing the required content for the Spanish-speaking clientele her client was hoping to add.
(Update: Feb. 2, 2018) After my wife showed her client a sample of how editing just the English text of the site could serve customers in two languages with a single site her client was thrilled that she could get the results she was after and not have to pay her web designer to duplicate the site in a new language.
My write up about the Hawaii False Alarm left me a little unsatisfied in that it really didn’t offer much in the way of actionable responses. Fortunately, better minds than mine came to the rescue today.
Everyone planning to launch a service or website should review it, whether they are a government organization or not. The U.S. Government has a lot of great resources for digital and content design (Honest!) for no charge, such as:
Erie’s article concludes with a long list of resources for people tasked with procuring government systems. Designers and developers can use those same resources to find out where they can help out and put their expertise and passion to work.
Hidden in this list is the disappointing observation that, “Government contractors can do incredible work, but the work is typically not set up for success.” Yet she continues to offer some supportive advice, “The key to getting the best out of a contract is to include usability testing and the digital service playbook in the statement of work, but also in breaking down the contract into the smallest pieces possible. 18F is doing groundbreaking work on this front and is happy to help” (Emphasis mine).
Their problems are really our responsibility
In the end, it’s really up to all of us as taxpayers. Erie quotes this tweet:
The challenge isn’t redesigning the user experience of a government system to avoid pushing the wrong button by mistake. That’s the easy part. The hard part is convincing a decision-maker to prioritize the redesign and allocate taxpayer dollars to fixing it.
I feel better knowing that there are so many ways to actually make the situation better. Hopefully, by adopting these improvements, the improvements will get as much press (or even 1/10 the press) as the Hawaii False Alarm and it will become easier and easier to improve these vital services.
OK, enough with the unsolicited design updates to the Hawaii civil defense notification system, please! While the UI design of the operator’s interface could be improved, considerably, that’s not the root cause of the problem.
For those who have been in a cave for the past week, a false alarm sounded through Hawaii last weekend, which has attracted no shortage of design critique and righteous condemnation of an unquestionably atrocious user interface. The fires of that outrage only grew stronger when a screenshot of the interface was published showing the UI used (later, it turns out that this was NOT the actual UI, but a mockup).
Now the State of Hawaii is saying the original screenshot shared with the media is merely an example and has shared a second image saying it is another example of the user interface. Neither screenshot shows the actual interface used by the operator. https://t.co/lVhYQYc30Dpic.twitter.com/VFDXpvFiZd
The error was initially attributed to “Human (operator) error.” To which the UI design community (as represented on Twitter) pointed out that the system designers bear some (if not most) of the responsibility for the error by designing (or allowing) an interface that made such an error so easy.
The article linked in the NNgroup tweet observes that, “People should not be blamed for errors caused by poorly designed systems.” I hope the appropriate authorities consider this when they determine the fate and future career of the operator who made the fateful click.
While, NNgroup’s article is titled, “What the Erroneous Hawaiian Missile Alert Can Teach Us About Error Prevention,” I would argue that it is preaching to the choir and is not teaching their readers anything they don’t already know. The article describes a list of design patterns that can help make errors such as occurred in Hawaii less probable, usability 101 stuff, yet misses the elephant in the room–the overall system in which the UI exists. If context is important, and it is, the context of the system, not just that one interaction must be considered before identifying any errors to fix or placing any blame.
By this, I mean, should you describe in the formal documentation the way a feature actually works or the way it is supposed to work?
tl;dr: Yes.
There is a lot of research that says software developers (and, I would imagine almost anyone else, but I haven’t studied that research) expect the documentation to be accurate, so reference documentation should describe how something ACTUALLY works. If “how it works” changes, the documentation should be updated to reflect that. Simple, right?
Well, if a feature is shipped that (let’s say) still has some room for improvement, your accurate documentation will highlight that. A real fear in the hearts of some product managers is that your accurate documentation could turn some customers away saying, “we need something that does X and your product’s documentation says that it doesn’t do X (yet).” Your product manager will have to weigh the cost of that vs. the cost of having the customer build their system around your product expecting “X” only to find out that it doesn’t. A decision that could get your product into market and/or into an unflattering TechCrunch article.
The problem with reference topics (of almost any sort) is that, individually, they don’t do much and don’t get a lot of attention (except, of course, when they do). Collectively, they tell your customers how much you value their time and their business.
…and why return on investment (ROI) is not the best metric to use for measuring content value.
I’ve been ruminating on the topic of content value (more than I usually do) since Tom Johnson published his essay on technical communication value last month. I’ve studied measurement, experimentation, and statistical process control in applications other than writing and I have also seen them repeatedly and painfully applied to writing. The results have been, almost without exception, anywhere from disappointing to destructive. Until this morning, I haven’t been able to articulate why. Thankfully, a post in Medium by Alan Cooper provided the shift in perspective to help me bring everything into focus. I’m passionate about this because it’s the new view of tech comm that is needed for the 21st century.
Writing is a process, but it’s not a manufacturing process
Alan Cooper’s post, titled “ROI Does Not Apply,” describes how “ROI is an industrial age term, applicable to companies that manufacture things in factories.” Writing is not a manufacturing process. Granted, there are some manufacturing-like elements of the writing process as you get closer to publishing the content—and honestly, making that part of the process as commodity-like as possible has some benefits. But, writers add the most value to the content where the process is complicated and non-linear: towards the beginning, where concepts, notions, and ideas are brought together to become a serial string of words. That’s were ROI and other productivity measures are inappropriate—they don’t measure what’s important to adding value. Continue reading “Why I’m passionate about content metrics”
Yet another study is out, this one from UC Berkeley: Most developers think we should spend more time on documentation, showing that developers, when asked, say that they want more documentation, or, in this case, need to spend more time working on (writing?) the documentation for the software they use and write. The list of related studies is long (by software-documentation-related-studies standards, anyway), a few of which I mention in A brief history of API Docs and in my bibliography.
I understand the the desire to ask developers (over and over, now) questions like “do you have enough documentation?” “what’s wrong with the documentation?” “What do you want to see more of in documentation?” and so on, when those are the questions on your mind. However, that type of question has been asked for over 15 years and the answers haven’t changed.
At this point, we should just assume that,
Developers will always tell you that they want more documentation.
They always have and they always will.
If you want to know why they express this need for more documentation, my hypothesis (based on previous research) is that it’s…
Because developers can’t find the documentation they need when they need it.
I’m working on a project for an international customer base, initially supporting the Spanish and English languages. Having worked on international projects before, I knew that I’d have to make some accommodations, but I was still, in the 21st century, surprised at how un-automatic the process still was to make it all work. The surprises I’m seeing are now less frequent, but I no longer trust that I won’t find another around the next corner.
The project
I’m developing a small patient automation system (the piClinic) for use in limited resource clinics in developing countries. While there is no shortage of Electronic Health Record (EHR) systems, they tend to work best in well-funded and well-supported clinics and hospitals. For everyone else (which is a rather large population) there are virtually no suitable systems, especially for small clinics in countries that do not (yet) need to support the comprehensive (and complex) data collection and reporting requirements for health information in the U.S.
The piClinic system is designed to fill the gap between zero automation and complete EHR systems until that gap can be closed or the clinic grows out of it and becomes able to install a more full-featured system. Given that much of the developing world speaks a language other than English, internationalization is something that needs to be built in from the start and not just bolted on as an afterthought. Continue reading “Wrestling with UTF-8”